The current BlockAssembler bench only tests on a mempool where all
transactions have 0 ancestors or descendants, which does not exercise
any of the package-handling logic in BlockAssembler
* Use SECP256K1_CONTEXT_NONE when creating signing context, as
SECP256K1_CONTEXT_SIGN is deprecated and unnecessary.
* Use secp256k1_static_context where applicable.
38941a703e refactor: Move `txmempool_entry.h` --> `kernel/mempool_entry.h` (Hennadii Stepanov)
Pull request description:
This PR addresses the https://github.com/bitcoin/bitcoin/pull/17786#discussion_r1027818360:
> why not move it to the right place, that is to `kernel/txmempool_entry.h`?
ACKs for top commit:
MarcoFalke:
review ACK 38941a703e📊
Tree-SHA512: 0145974b63b67ca1d9d89af2dd9d4438beca480c16a563f330da05fec49b8394d7ba20ed83cf7d50b2e19454e006978ebed42b0e07887b98d00210f3201ce9ba
13d9760829 test: load wallet, coverage for crypted keys (furszy)
373c99633e refactor: move DuplicateMockDatabase to wallet/test/util.h (furszy)
ee7a984f85 refactor: unify test/util/wallet.h with wallet/test/util.h (furszy)
cc5a5e8121 wallet: bugfix, invalid crypted key "checksum_valid" set (furszy)
Pull request description:
At wallet load time, the crypted key "checksum_valid" variable is always set to false. Which, on every wallet decryption call, forces the process to re-write all the ckeys to db when it's not needed.
Note:
The first commit fixes the issue, the two commits in the middle are cleanups so `DuplicateMockDatabase`
can be used without duplicating code. And, the last one is pure test coverage for the crypted keys loading
process.
Includes test coverage for the following scenarios:
1) "All ckeys checksums valid" test:
Loads an encrypted wallet with all the crypted keys with a valid checksum and
verifies that 'CWallet::Unlock' doesn't force an entire crypted keys re-write.
(we force a complete ckeys re-write if we find any missing crypted key checksum
during the wallet loading process)
2) "Missing checksum in one ckey" test:
Verifies that loading up a wallet with, at least one, 'ckey' with no checksum
triggers a complete re-write of the crypted keys.
3) "Invalid ckey checksum error" test:
Verifies that loading up a ckey with an invalid checksum stops the wallet loading
process with a corruption error.
4) "Invalid ckey pubkey error" test:
Verifies that loading up a ckey with an invalid pubkey stops the wallet loading
process with a corruption error.
ACKs for top commit:
achow101:
ACK 13d9760829
aureleoules:
ACK 13d9760829
Tree-SHA512: 9ea630ee4a355282fbeee61ca04737294382577bb4b2631f50e732568fdab8f72491930807fbda58206446c4f26200cdc34d8afa14dbe1241aec713887d06a0b
files share the same purpose, and we shouldn't have wallet code
inside the test directory.
This later is needed to use wallet util functions in the bench
and test binaries without be forced to duplicate them.
c8dc0e3eaa refactor: Inline `CTxMemPoolEntry` class's functions (Hennadii Stepanov)
75bbe594e5 refactor: Move `CTxMemPoolEntry` class to its own module (Hennadii Stepanov)
Pull request description:
This PR:
- gets rid of the `policy/fees` -> `txmempool` -> `policy/fees` circular dependency
- is an alternative to #13949, which nukes only one circular dependency
ACKs for top commit:
ryanofsky:
Code review ACK c8dc0e3eaa. Just include and whitespace changes since last review, and there's a moveonly commit now so it's very easy to review
theStack:
Code-review ACK c8dc0e3eaa
glozow:
utACK c8dc0e3eaa, agree these changes are an improvement.
Tree-SHA512: 36ece824e6ed3ab1a1e198b30a906c8ac12de24545f840eb046958a17315ac9260c7de26e11e2fbab7208adc3d74918db7a7e389444130f8810548ca2e81af41
fa84df1f03 scripted-diff: wallet: rename AvailableCoinsParams members to snake_case (furszy)
61c2265629 wallet: group AvailableCoins filtering parameters in a single struct (furszy)
f0f6a3577b RPC: listunspent, add "include immature coinbase" flag (furszy)
Pull request description:
Simple PR; adds a "include_immature_coinbase" flag to `listunspent` to include the immature coinbase UTXOs on the response. Requested by #25728.
ACKs for top commit:
danielabrozzoni:
reACK fa84df1f03
achow101:
ACK fa84df1f03
aureleoules:
reACK fa84df1f03
kouloumos:
reACK fa84df1f03
theStack:
Code-review ACK fa84df1f03
Tree-SHA512: 0f3544cb8cfd0378a5c74594480f78e9e919c6cfb73a83e0f3112f8a0132a9147cf846f999eab522cea9ef5bd3ffd60690ea2ca367dde457b0554d7f38aec792
db929893ef Faster -reindex by initially deserializing only headers (Larry Ruane)
c72de9990a util: add CBufferedFile::SkipTo() to move ahead in the stream (Larry Ruane)
48a68908ba Add LoadExternalBlockFile() benchmark (Larry Ruane)
Pull request description:
### Background
During the first part of reindexing, `LoadExternalBlockFile()` sequentially reads raw blocks from the `blocks/blk00nnn.dat` files (rather than receiving them from peers, as with initial block download) and eventually adds all of them to the block index. When an individual block is initially read, it can't be immediately added unless all its ancestors have been added, which is rare (only about 8% of the time), because the blocks are not sorted by height. When the block can't be immediately added to the block index, its disk location is saved in a map so it can be added later. When its parent is later added to the block index, `LoadExternalBlockFile()` reads and deserializes the block from disk a second time and adds it to the block index. Most blocks (92%) get deserialized twice.
### This PR
During the initial read, it's rarely useful to deserialize the entire block; only the header is needed to determine if the block can be added to the block index immediately. This change to `LoadExternalBlockFile()` initially deserializes only a block's header, then deserializes the entire block only if it can be added immediately. This reduces reindex time on mainnet by 7 hours on a Raspberry Pi, which translates to around a 25% reduction in the first part of reindexing (adding blocks to the index), and about a 6% reduction in overall reindex time.
Summary: The performance gain is the result of deserializing each block only once, except its header which is deserialized twice, but the header is only 80 bytes.
ACKs for top commit:
andrewtoth:
ACK db929893ef
achow101:
ACK db929893ef
aureleoules:
ACK db929893ef - minor changes and new benchmark since last review
theStack:
re-ACK db929893ef
stickies-v:
re-ACK db929893e
Tree-SHA512: 5a5377192c11edb5b662e18f511c9beb8f250bc88aeadf2f404c92c3232a7617bade50477ebf16c0602b9bd3b68306d3ee7615de58acfd8cae664d28bb7b0136
This change allows to simplify CI tests, and makes it easier to
integrate the `bench_bitcoin` binary into CMake custom targets or
commands, as `COMMAND` does not support output redirection
Goal 1:
Benchmark the transaction creation process for pre-selected-inputs only.
Setting `m_allow_other_inputs=false` to disallow the wallet to include coins automatically.
Goal 2:
Benchmark the transaction creation process for pre-selected-inputs and coin selection.
-----------------------
Benchmark Setup:
1) Generates a 5k blockchain, loading the wallet with 5k transactions with two outputs each.
2) Fetch 4 random UTXO from the wallet's available coins and pre-select them as inputs inside CoinControl.
Benchmark (Goal 1):
Call `CreateTransaction` providing the coin control, who has set `m_allow_other_inputs=false` and
the manually selected coins.
Benchmark (Goal 2):
Call `CreateTransaction` providing the coin control, who has set `m_allow_other_inputs=true` and
the manually selected coins.
3e9d0bea8d build: only run high priority benchmarks in 'make check' (furszy)
466b54bd4a bench: surround main() execution with try/catch (furszy)
3da7cd2a76 bench: explicitly make all current benchmarks "high" priority (furszy)
05b8c76232 bench: add "priority level" to the benchmark framework (furszy)
f1593780b8 bench: place benchmark implementation inside benchmark namespace (furszy)
Pull request description:
This is from today's meeting, a simple "priority level" for the benchmark framework.
Will allow us to run certain benchmarks while skip non-prioritized ones in `make check`.
By default, `bench_bitcoin` will run all the benchmarks. `make check`will only run the high priority ones,
and have marked all the existent benchmarks as "high priority" to retain the current behavior.
Could test it by modifying any benchmark priority to something different from "high", and
run `bench_bitcoin -priority-level=high` and/or `bench_bitcoin -priority-level=medium,low`
(the first command will skip the modified bench while the second one will include it).
Note: the second commit could be avoided by having a default arg value for the priority
level but.. an explicit set in every `BENCHMARK` macro call makes it less error-prone.
ACKs for top commit:
kouloumos:
re-ACK 3e9d0bea8d
achow101:
ACK 3e9d0bea8d
theStack:
re-ACK 3e9d0bea8d
stickies-v:
re-ACK 3e9d0bea8d
Tree-SHA512: ece59bf424c5fc1db335f84caa507476fb8ad8c6151880f1f8289562e17023aae5b5e7de03e8cbba6337bf09215f9be331e9ef51c791c43bce43f7446813b054
and also fix spelling in test/lint/lint-locale-dependence.py not caught by the
spelling linter and fix up a paragraph we are touching here in test/README.md.
8cd21bb279 refactor: improve readability for AttemptSelection (josibake)
f47ff71761 test: only run test for descriptor wallets (josibake)
0760ce0b9e test: add missing BOOST_ASSERT (josibake)
db09aec937 wallet: switch to new shuffle, erase, push_back (josibake)
b6b50b0f2b scripted-diff: Uppercase function names (josibake)
3f27a2adce refactor: add new helper methods (josibake)
f5649db9d5 refactor: add UNKNOWN OutputType (josibake)
Pull request description:
This PR is to address follow-ups for #24584, specifically:
* Remove redundant, hard-to-read code by adding a new `OutputType` and adding shuffle, erase, and push_back methods for `CoinsResult`
* Add missing `BOOST_ASSERT` to unit test
* Ensure functional test only runs if using descriptor wallets
* Improve readability of `AttemptSelection` by removing triple-nested if statement
Note for reviewers: commit `refactor: add new helper methods` should throw an "unused function warning"; the function is used in the next commit. Also, commit `wallet: switch to new shuffle, erase, push_back` will fail to compile, but this is fixed in the next commit with a scripted-diff. the commits are separate like this (code change then scripted-diff) to improve legibility.
ACKs for top commit:
achow101:
ACK 8cd21bb279
aureleoules:
ACK 8cd21bb279.
LarryRuane:
Concept, code review ACK 8cd21bb279
furszy:
utACK 8cd21bb2. Left a small, non-blocking, comment.
Tree-SHA512: a1bbc5962833e3df4f01a4895d8bd748cc4c608c3f296fd94e8afd8797b8d2e94e7bd44d598bd76fa5c9f5536864f396fcd097348fa0bb190a49a86b0917d60e
switch to new methods, remove old code. this also
updates the Size, All, and Clear methods to now use
the coins map.
this commit is not strictly a refactor because previously
coin selection was never run over the UNKNOWN type until the last
step when being run over all. now that we are iterating over each,
it is run over UNKNOWN but this is expected to be empty most of the time.
Co-authored-by: furszy <matiasfurszyfer@protonmail.com>
a23cca56c0 refactor: Replace BResult with util::Result (Ryan Ofsky)
Pull request description:
Rename `BResult` class to `util::Result` and update the class interface to be more compatible with `std::optional` and with a full-featured result class implemented in https://github.com/bitcoin/bitcoin/pull/25665. Motivation for this change is to update existing `BResult` usages now so they don't have to change later when more features are added in https://github.com/bitcoin/bitcoin/pull/25665.
This change makes the following improvements originally implemented in https://github.com/bitcoin/bitcoin/pull/25665:
- More explicit API. Drops potentially misleading `BResult` constructor that treats any bilingual string argument as an error. Adds `util::Error` constructor so it is never ambiguous when a result is being assigned an error or non-error value.
- Better type compatibility. Supports `util::Result<bilingual_str>` return values to hold translated messages which are not errors.
- More standard and consistent API. `util::Result` supports most of the same operators and methods as `std::optional`. `BResult` had a less familiar interface with `HasRes`/`GetObj`/`ReleaseObj` methods. The Result/Res/Obj naming was also not internally consistent.
- Better code organization. Puts `src/util/` code in the `util::` namespace so naming reflects code organization and it is obvious where the class is coming from. Drops "B" from name because it is undocumented what it stands for (bilingual?)
- Has unit tests.
ACKs for top commit:
MarcoFalke:
ACK a23cca56c0 🏵
jonatack:
ACK a23cca56c0
Tree-SHA512: 2769791e08cd62f21d850aa13fa7afce4fb6875a9cedc39ad5025150dbc611c2ecfd7b3aba8b980a79fde7fbda13babdfa37340633c69b501b6e89727bad5b31
Rename `BResult` class to `util::Result` and update the class interface to be
more compatible with `std::optional` and with a full-featured result class
implemented in https://github.com/bitcoin/bitcoin/pull/25665. Motivation for
this change is to update existing `BResult` usages now so they don't have to
change later when more features are added in #25665.
This change makes the following improvements originally implemented in #25665:
- More explicit API. Drops potentially misleading `BResult` constructor that
treats any bilingual string argument as an error. Adds `util::Error`
constructor so it is never ambiguous when a result is being assigned an error
or non-error value.
- Better type compatibility. Supports `util::Result<bilingual_str>` return
values to hold translated messages which are not errors.
- More standard and consistent API. `util::Result` supports most of the same
operators and methods as `std::optional`. `BResult` had a less familiar
interface with `HasRes`/`GetObj`/`ReleaseObj` methods. The Result/Res/Obj
naming was also not internally consistent.
- Better code organization. Puts `src/util/` code in the `util::` namespace so
naming reflects code organization and it is obvious where the class is coming
from. Drops "B" from name because it is undocumented what it stands for
(bilingual?)
- Has unit tests.
71d1d13627 test: add unit test for AvailableCoins (josibake)
da03cb41a4 test: functional test for new coin selection logic (josibake)
438e04845b wallet: run coin selection by `OutputType` (josibake)
77b0707206 refactor: use CoinsResult struct in SelectCoins (josibake)
2e67291ca3 refactor: store by OutputType in CoinsResult (josibake)
Pull request description:
# Concept
Following https://github.com/bitcoin/bitcoin/pull/23789, Bitcoin Core wallet will now generate a change address that matches the payment address type. This improves privacy by not revealing which of the outputs is the change at the time of the transaction in scenarios where the input address types differ from the payment address type. However, information about the change can be leaked in a later transaction. This proposal attempts to address that concern.
## Leaking information in a later transaction
Consider the following scenario:
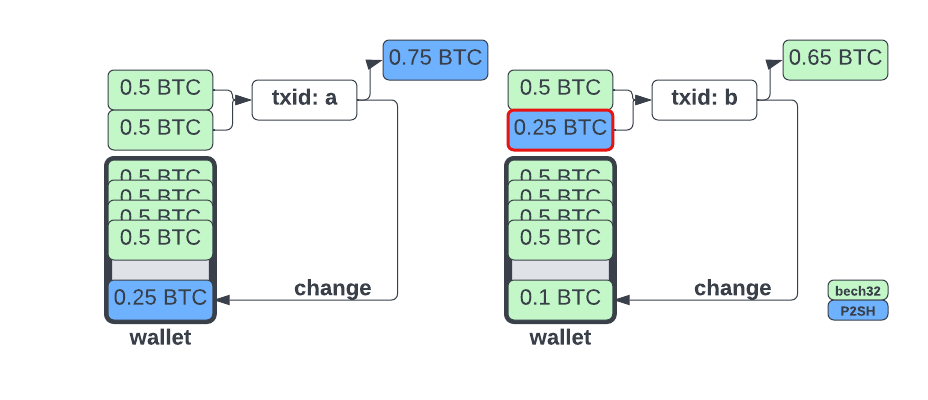
1. Alice has a wallet with bech32 type UTXOs and pays Bob, who gives her a P2SH address
2. Alice's wallet generates a P2SH change output, preserving her privacy in `txid: a`
3. Alice then pays Carol, who gives her a bech32 address
4. Alice's wallet combines the P2SH UTXO with a bech32 UTXO and `txid: b` has two bech32 outputs
From a chain analysis perspective, it is reasonable to infer that the P2SH input in `txid: b` was the change from `txid: a`. To avoid leaking information in this scenario, Alice's wallet should avoid picking the P2SH output and instead fund the transaction with only bech32 Outputs. If the payment to Carol can be funded with just the P2SH output, it should be preferred over the bech32 outputs as this will convert the P2SH UTXO to bech32 UTXOs via the payment and change outputs of the new transaction.
**TLDR;** Avoid mixing output types, spend non-default `OutputTypes` when it is economical to do so.
# Approach
`AvailableCoins` now populates a struct, which makes it easier to access coins by `OutputType`. Coin selection tries to find a funding solution by each output type and chooses the most economical by waste metric. If a solution can't be found without mixing, coin selection runs over the entire wallet, allowing mixing, which is the same as the current behavior.
I've also added a functional test (`test/functional/wallet_avoid_mixing_output_types.py`) and unit test (`src/wallet/test/availablecoins_tests.cpp`.
ACKs for top commit:
achow101:
re-ACK 71d1d13627
aureleoules:
ACK 71d1d13627.
Xekyo:
reACK 71d1d13627 via `git range-diff master 6530d19 71d1d13`
LarryRuane:
ACK 71d1d13627
Tree-SHA512: 2e0716efdae5adf5479446fabc731ae81d595131d3b8bade98b64ba323d0e0c6d964a67f8c14c89c428998bda47993fa924f3cfca1529e2bd49eaa4e31b7e426
Run coin selection on each OutputType separately, choosing the best
solution according to the waste metric.
This is to avoid mixing UTXOs that are of different OutputTypes,
which can hurt privacy.
If no single OutputType can fund the transaction, then coin selection
considers the entire wallet, potentially mixing (current behavior).
This is done inside AttemptSelection so that all OutputTypes are
considered at each back-off in coin selection.
Pass the whole CoinsResult struct to SelectCoins instead of only a
vector. This means we now have to remove preselected coins from each
OutputType vector and shuffle each vector individually.
Pass the whole CoinsResult struct to AttemptSelection. This involves
moving the logic in AttemptSelection to a newly named function,
ChooseSelectionResult. This will allow us to run ChooseSelectionResult
over each OutputType in a later commit. This ensures the backoffs work
properly.
Update unit and bench tests to use CoinResult.
111ea3ab71 wallet: refactor GetNewDestination, use BResult (furszy)
22351725bc send: refactor CreateTransaction flow to return a BResult<CTransactionRef> (furszy)
198fcca162 wallet: refactor, include 'FeeCalculation' inside 'CreatedTransactionResult' (furszy)
7a45c33d1f Introduce generic 'Result' class (furszy)
Pull request description:
Based on a common function signature pattern that we have all around the sources:
```cpp
bool doSomething(arg1, arg2, arg3, arg4, &result_obj, &error_string) {
// do something...
if (error) {
error_string = "something bad happened";
return false;
}
result = goodResult;
return true;
}
```
Introduced a generic class `BResult` that encapsulate the function boolean result, the result object (in case of having it) and, in case of failure, the string error reason.
Obtaining in this way cleaner function signatures and removing boilerplate code:
```cpp
BResult<Obj> doSomething(arg1, arg2, arg3, arg4) {
// do something...
if (error) return "something bad happened";
return goodResult;
}
```
Same cleanup applies equally to the function callers' side as well. There is no longer need to add the error string and the result object declarations before calling the function:
Before:
```cpp
Obj result_obj;
std::string error_string;
if (!doSomething(arg1, arg2, arg3, arg4, result_obj, error_string)) {
LogPrintf("Error: %s", error_string);
}
return result_obj;
```
Now:
```cpp
BResult<Obj> op_res = doSomething(arg1, arg2, arg3, arg4);
if (!op_res) {
LogPrintf("Error: %s", op_res.GetError());
}
return op_res.GetObjResult();
```
### Initial Implementation:
Have connected this new concept to two different flows for now:
1) The `CreateTransaction` flow. --> 7ba2b87c
2) The `GetNewDestination` flow. --> bcee0912
Happy note: even when introduced a new class into the sources, the amount of lines removed is almost equal to added ones :).
Extra note: this work is an extended version (and a decoupling) of the work that is inside #24845 (which does not contain the `GetNewDestination` changes nor the inclusion of the `FeeCalculation` field inside `CreatedTransactionResult`).
ACKs for top commit:
achow101:
ACK 111ea3ab71
w0xlt:
reACK 111ea3ab71
theStack:
re-ACK 111ea3ab71
MarcoFalke:
review ACK 111ea3ab71🎏
Tree-SHA512: 6d84d901a4cb923727067f25ff64542a40edd1ea84fdeac092312ac684c34e3688a52ac5eb012717d2b73f4cb742b9d78e458eb0e9cb9d6d72a916395be91f69
d54c5c8b1b wallet: use CCoinControl to estimate signature size (S3RK)
a94659c84e wallet: replace GetTxSpendSize with CalculateMaximumSignedInputSize (S3RK)
Pull request description:
Currently `DummySignTx` and `DummySignInput` use different ways to determine signature size.
This PR unifies the way wallet estimates signature size for various inputs.
Instead of passing boolean flags from calling code the `use_max_sig` is now calculated at the place of signature creation using information available in `CCoinControl`
ACKs for top commit:
achow101:
ACK d54c5c8b1b
theStack:
Code-review ACK d54c5c8b1b
Tree-SHA512: e790903ad4683067070aa7dbf7434a1bd142282a5bc425112e64d88d27559f1a2cd60c68d6022feaf6b845237035cb18ece10f6243d719ba28173b69bd99110a
e734228d85 Update GCSFilter benchmarks (Calvin Kim)
aee9a8140b Add GCSFilterDecodeSkipCheck benchmark (Patrick Strateman)
299023c1d9 Add GCSFilterDecode and GCSBlockFilterGetHash benchmarks. (Patrick Strateman)
b0a53d50d9 Make sanity check in GCSFilter constructor optional (Patrick Strateman)
Pull request description:
This PR picks up the abandoned #19280
BlockFilterIndex was depending on `GolombRiceDecode()` during the filter decode to sanity check that the filter wasn't corrupt. However, we can check for corruption by ensuring that the encoded blockfilter's hash matches up with the one stored in the index database.
Benchmarks that were added in #19280 showed that checking the hash is much faster.
The benchmarks were changed to nanobench and the relevant benchmarks were like below, showing a clear win for the hash check method.
```
| ns/elem | elem/s | err% | ins/elem | bra/elem | miss% | total | benchmark
|--------------------:|--------------------:|--------:|----------------:|---------------:|--------:|----------:|:----------
| 531.40 | 1,881,819.43 | 0.3% | 3,527.01 | 411.00 | 0.2% | 0.01 | `DecodeCheckedGCSFilter`
| 258,220.50 | 3,872.66 | 0.1% | 2,990,092.00 | 586,706.00 | 1.7% | 0.01 | `DecodeGCSFilter`
| 13,036.77 | 76,706.09 | 0.3% | 64,238.24 | 513.04 | 0.2% | 0.01 | `BlockFilterGetHash`
```
ACKs for top commit:
mzumsande:
Code Review ACK e734228d85
theStack:
Code-review ACK e734228d85
stickies-v:
ACK e734228d85
ryanofsky:
Code review ACK e734228d85, with caveat that I mostly paid attention to the main code, not the changes to the benchmark. Only changes since last review were changes to the benchmark code.
Tree-SHA512: 02b86eab7b554e1a57a15b17a4d6d71faa91b556c637b0da29f0c9ee76597a110be8e3b4d0c158d4cab04af0623de18b764837be0ec2a72afcfe1ad9c78a83c6
e673d8b475 bench: Enable loading benchmarks depending on what's compiled (Andrew Chow)
4af3547eba bench: Use mock wallet database for wallet loading benchmark (Andrew Chow)
49910f255f sqlite: Use in-memory db instead of temp for mockdb (Andrew Chow)
a1080802f8 walletdb: Create a mock database of specific type (Andrew Chow)
7c0d34476d bench: reduce the number of txs in wallet for wallet loading bench (Andrew Chow)
f85b54ed27 bench: Add transactions directly instead of mining blocks (Andrew Chow)
d94244c4bf bench: reduce number of epochs for wallet loading benchmark (Andrew Chow)
817c051364 bench: use unsafesqlitesync in wallet loading benchmark (Andrew Chow)
9e404a9831 bench: Remove minEpochIterations from wallet loading benchmark (Andrew Chow)
Pull request description:
`minEpochIterations` is probably unnecessary to set, so removing it makes the runtime much faster.
ACKs for top commit:
Rspigler:
tACK e673d8b475
furszy:
Code review ACK e673d8b4, nice PR.
glozow:
Concept ACK e673d8b475. For each commit, verified that there was a performance improvement without negating the purpose of the bench, and made some effort to verify that the code is correct.
Tree-SHA512: 9337352ef846cf18642d5c14546c5abc1674b4975adb5dc961a1a276ca91f046b83b7a5e27ea6cd26264b96ae71151e14055579baf36afae7692ef4029800877
d273e53b6e bench/rpc_mempool: Create ChainTestingSetup, use its CTxMemPool (Carl Dong)
020caba3df bench: Use existing CTxMemPool in TestingSetup (Carl Dong)
86e732def3 scripted-diff: test: Use CTxMemPool in TestingSetup (Carl Dong)
213457e170 test/policyestimator: Use ChainTestingSetup's CTxMemPool (Carl Dong)
319f0ceeeb rest/getutxos: Don't construct empty mempool (Carl Dong)
03574b956a tree-wide: clang-format CTxMemPool references (Carl Dong)
Pull request description:
This is part of the `libbitcoinkernel` project: #24303, https://github.com/bitcoin/bitcoin/projects/18
This PR reduces the number of call sites where we explicitly construct CTxMemPool. This is done in preparation for later PRs which decouple the mempool module from `ArgsManager`, eventually all of libbitcoinkernel will be decoupled from `ArgsManager`.
The changes in this PR:
- Allows us to have less code churn as we modify `CTxMemPool`'s constructor in later PRs
- In many cases, we can make use of existing `CTxMemPool` instances, getting rid of extraneous constructions
- In other cases, we construct a `ChainTestingSetup` and use the `CTxMemPool` there, so that we can rely on the logic in `setup_common` to set things up correctly
## Notes for Reviewers
### A note on using existing mempools
When evaluating whether or not it's appropriate to use an existing mempool in a `*TestingSetup` struct, the key is to make sure that the mempool has the same lifetime as the `*TestingSetup` struct.
Example 1: In [`src/fuzz/tx_pool.cpp`](b4f686952a/src/test/fuzz/tx_pool.cpp), the `TestingSetup` is initialized in `initialize_tx_pool` and lives as a static global, while the `CTxMemPool` is in the `tx_pool_standard` fuzz target, meaning that each time the `tx_pool_standard` fuzz target gets run, a new `CTxMemPool` is created. If we were to use the static global `TestingSetup`'s CTxMemPool we might run into problems since its `CTxMemPool` will carry state between subsequent runs. This is why we don't modify `src/fuzz/tx_pool.cpp` in this PR.
Example 2: In [`src/bench/mempool_eviction.cpp`](b4f686952a/src/bench/mempool_eviction.cpp), we see that the `TestingSetup` is in the same scope as the constructed `CTxMemPool`, so it is safe to use its `CTxMemPool`.
### A note on checking `CTxMemPool` ctor call sites
After the "tree-wide: clang-format CTxMemPool references" commit, you can find all `CTxMemPool` ctor call sites with the following command:
```sh
git grep -E -e 'make_unique<CTxMemPool>' \
-e '\bCTxMemPool\s+[^({;]+[({]' \
-e '\bCTxMemPool\s+[^;]+;' \
-e '\bnew\s+CTxMemPool\b'
```
At the end of the PR, you will find that there are still quite a few call sites that we can seemingly get rid of:
```sh
$ git grep -E -e 'make_unique<CTxMemPool>' -e '\bCTxMemPool\s+[^({;]+[({]' -e '\bCTxMemPool\s+[^;]+;' -e '\bnew\s+CTxMemPool\b'
# rearranged for easier explication
src/init.cpp: node.mempool = std::make_unique<CTxMemPool>(node.fee_estimator.get(), mempool_check_ratio);
src/test/util/setup_common.cpp: m_node.mempool = std::make_unique<CTxMemPool>(m_node.fee_estimator.get(), 1);
src/rpc/mining.cpp: CTxMemPool empty_mempool;
src/test/util/setup_common.cpp: CTxMemPool empty_pool;
src/bench/mempool_stress.cpp: CTxMemPool pool;
src/bench/mempool_stress.cpp: CTxMemPool pool;
src/test/fuzz/rbf.cpp: CTxMemPool pool;
src/test/fuzz/tx_pool.cpp: CTxMemPool tx_pool_{/*estimator=*/nullptr, /*check_ratio=*/1};
src/test/fuzz/tx_pool.cpp: CTxMemPool tx_pool_{/*estimator=*/nullptr, /*check_ratio=*/1};
src/test/fuzz/validation_load_mempool.cpp: CTxMemPool pool{};
src/txmempool.h: /** Create a new CTxMemPool.
```
Let's break them down one by one:
```
src/init.cpp: node.mempool = std::make_unique<CTxMemPool>(node.fee_estimator.get(), mempool_check_ratio);
src/test/util/setup_common.cpp: m_node.mempool = std::make_unique<CTxMemPool>(m_node.fee_estimator.get(), 1);
```
Necessary
-----
```
src/rpc/mining.cpp: CTxMemPool empty_mempool;
src/test/util/setup_common.cpp: CTxMemPool empty_pool;
```
These are fixed in #25223 where we stop requiring the `BlockAssembler` to have a `CTxMemPool` if it's not going to consult it anyway (as is the case in these two call sites)
-----
```
src/bench/mempool_stress.cpp: CTxMemPool pool;
src/bench/mempool_stress.cpp: CTxMemPool pool;
```
Fixed in #24927.
-----
```
src/test/fuzz/rbf.cpp: CTxMemPool pool;
src/test/fuzz/tx_pool.cpp: CTxMemPool tx_pool_{/*estimator=*/nullptr, /*check_ratio=*/1};
src/test/fuzz/tx_pool.cpp: CTxMemPool tx_pool_{/*estimator=*/nullptr, /*check_ratio=*/1};
src/test/fuzz/validation_load_mempool.cpp: CTxMemPool pool{};
```
These are all cases where we don't want the `CTxMemPool` state to persist between runs, see the previous section "A note on using existing mempools"
-----
```
src/txmempool.h: /** Create a new CTxMemPool.
```
It's a comment (someone link me to a grep that understands syntax plz thx)
ACKs for top commit:
laanwj:
Code review ACK d273e53b6e
Tree-SHA512: c4ff3d23217a7cc4a7145defc7b901725073ef73bcac3a252ed75f672c87e98ca0368d1d8c3f606b5b49f641e7d8387d26ef802141b650b215876f191fb6d5f9
d2f8f1b307 use testing setup mempool in ComplexMemPool bench (glozow)
aecc332a71 create and use mempool transactions using real coins in MempoolCheck (glozow)
2118750631 [test util] to populate mempool with random transactions/packages (glozow)
5374dfc4e3 [test util] use -checkmempool for TestingSetup mempool check ratio (glozow)
d7d9c7b266 [test util] add chain name to TestChain100Setup ctor (glozow)
Pull request description:
Fixes #24634 by using the `testing_setup`'s actual mempool rather than a locally-declared mempool for running `check()`.
Also creates a test utility for populating the mempool with a bunch of random transactions. I imagine this could be useful in other places as well; it was necessary here because we needed the mempool to contain transactions *spending coins available in the current chainstate*. The existing `CreateOrderedCoins()` is insufficient because it creates coins out of thin air.
Also implements the separate suggestion to use the `TestingSetup` mempool in `ComplexMemPool` bench.
ACKs for top commit:
laanwj:
Code review ACK d2f8f1b307
Tree-SHA512: 44ab5a9e55b126b5a5bc33f05fbad1380b9c43c84736c7cf487be025e0e3f5d75216ccf5a3088b0935da817e3dacfba99d2885f75bcb6e7eaa24cd20a82c24c8
{kind=link}