Remove the variant of ChaCha20Poly1305 AEAD that was previously added in
anticipation of BIP324 using it. BIP324 was updated to instead use rekeying
wrappers around otherwise unmodified versions of the ChaCha20 stream cipher
and the ChaCha20Poly1305 AEAD as specified in RFC8439.
6b605b91c1 [fuzz] Add MiniMiner target + diff fuzz against BlockAssembler (glozow)
3f3f2d59ea [unit test] GatherClusters and MiniMiner unit tests (glozow)
59afcc8354 Implement Mini version of BlockAssembler to calculate mining scores (glozow)
56484f0fdc [mempool] find connected mempool entries with GatherClusters(…) (glozow)
Pull request description:
Implement Mini version of BlockAssembler to calculate mining scores
Run the mining algorithm on a subset of the mempool, only disturbing the
mempool to copy out fee information for relevant entries. Intended to be
used by wallet to calculate amounts needed for fee-bumping unconfirmed
transactions.
From comments of sipa and glozow below:
> > In what way does the code added here differ from the real block assembly code?
>
> * Only operates on the relevant transactions rather than full mempool
> * Has the ability to remove transactions that will be replaced so they don't impact their ancestors
> * Does not hold mempool lock outside of the constructor, makes copies of the entries it needs instead (though I'm not sure if this has an effect in practice)
> * Doesn't do the sanity checks like keeping weight within max block weight and `IsFinalTx()`
> * After the block template is built, additionally calculates fees to bump remaining ancestor packages to target feerate
ACKs for top commit:
achow101:
ACK 6b605b91c1
Xekyo:
> ACK [6b605b9](6b605b91c1) modulo `miniminer_overlap` test.
furszy:
ACK 6b605b91 modulo `miniminer_overlap` test.
theStack:
Code-review ACK 6b605b91c1
Tree-SHA512: f86a8b4ae0506858a7b15d90f417ebceea5038b395c05c825e3796123ad3b6cb8a98ebb948521316802a4c6d60ebd7041093356b1e2c2922a06b3b96b3b8acb6
1b1ffbd014 Build: Log when test -f fails in Makefile (TheCharlatan)
541012e621 Build: Use AM_V_GEN in Makefiles where appropriate (TheCharlatan)
Pull request description:
This PR triages some behavior around Makefile recipe echoing suppression.
When generating new files as part of the Makefile the recipe is sometimes suppressed with $(AM_V_GEN) and sometimes with `@`. We should prefer $(AM_V_GEN), since this also prints the lines in silent mode. This is arguably more in style with the current recipe echoing.
Before:
`Generated test/data/script_tests.json.h`
Now:
` GEN test/data/script_tests.json.h`
A side effect of this change is that the recipe for generating build.h is now echoed on each make run. Arguably this makes its generation more transparent.
Sometimes the error emitted by `test -f` is currently thrown without any logging. This makes it a bit harder to debug. Instead, print a helpful log message to point the developer in the right direction.
Alternatively this could have been implemented by just removing the recipe echo suppression (@), but the subsequent make output became too noisy.
ACKs for top commit:
fanquake:
ACK 1b1ffbd014
Tree-SHA512: e31869fab25e72802b692ce6735f9561912caea903c1577101b64c9cb115c98de01a59300e8ffe7b05b998345c1b64a79226231d7d1453236ac338c62dc9fbb3
9f947fc3d4 Use PoolAllocator for CCoinsMap (Martin Leitner-Ankerl)
5e4ac5abf5 Call ReallocateCache() on each Flush() (Martin Leitner-Ankerl)
1afca6b663 Add PoolResource fuzzer (Martin Leitner-Ankerl)
e19943f049 Calculate memory usage correctly for unordered_maps that use PoolAllocator (Martin Leitner-Ankerl)
b8401c3281 Add pool based memory resource & allocator (Martin Leitner-Ankerl)
Pull request description:
A memory resource similar to `std::pmr::unsynchronized_pool_resource`, but optimized for node-based containers. The goal is to be able to cache more coins with the same memory usage, and allocate/deallocate faster.
This is a reimplementation of #22702. The goal was to implement it in a way that is simpler to review & test
* There is now a generic `PoolResource` for allocating/deallocating memory. This has practically the same API as `std::pmr::memory_resource`. (Unfortunately I cannot use std::pmr because libc++ simply doesn't implement that API).
* Thanks to sipa there is now a fuzzer for PoolResource! On a fast machine I ran it for ~770 million executions without finding any issue.
* The estimation of the correct node size is now gone, PoolResource now has multiple pools and just needs to be created large enough to have space for the unordered_map nodes.
I ran benchmarks with #22702, mergebase, and this PR. Frequency locked Intel i7-8700, clang++ 13.0.1 to reindex up to block 690000.
```sh
bitcoind -dbcache=5000 -assumevalid=00000000000000000002a23d6df20eecec15b21d32c75833cce28f113de888b7 -reindex-chainstate -printtoconsole=0 -stopatheight=690000
```
The performance is practically identical with #22702, just 0.4% slower. It's ~21% faster than master:


Note that on cache drops mergebase's memory doesnt go so far down because it does not free the `CCoinsMap` bucket array.

ACKs for top commit:
LarryRuane:
ACK 9f947fc3d4
achow101:
re-ACK 9f947fc3d4
john-moffett:
ACK 9f947fc3d4
jonatack:
re-ACK 9f947fc3d4
Tree-SHA512: 48caf57d1775875a612b54388ef64c53952cd48741cacfe20d89049f2fb35301b5c28e69264b7d659a3ca33d4c714d47bafad6fd547c4075f08b45acc87c0f45
3153e7d779 [fuzz] Add HeadersSyncState target (dergoegge)
53552affca [headerssync] Make m_commit_offset protected (dergoegge)
Pull request description:
This adds a fuzz target for the `HeadersSyncState` class.
I am unsure how well this is able to cover the logic since it is just processing unserialized CBlockHeaders straight from the fuzz input (headers are sometimes made continuous). However, it does manage to get to the redownload phase so i thought it is better then not having fuzzing at all.
It would also be nice to fuzz the p2p logic that is using `HeadersSyncState` (e.g. `TryLowWorkHeadersSync`, `IsContinuationOfLowWorkHeadersSync`) but that likely requires some more work (refactoring👻).
ACKs for top commit:
mzumsande:
ACK 3153e7d779
Tree-SHA512: 8a4630ceeeb30e4eeabaa8eb5491d98f0bf900efe7cda07384eaac9f2afaccfbcaa979cc1cc7f0b6ca297a8f5c17a7759f94809dd87eb87d35348d847c83e8ab
A memory resource similar to std::pmr::unsynchronized_pool_resource, but
optimized for node-based containers.
Co-Authored-By: Pieter Wuille <pieter@wuille.net>
802cc1ef53 Deduplicate bitcoind and bitcoin-qt init code (Ryan Ofsky)
d172b5c671 Add InitError(error, details) overload (Ryan Ofsky)
3db2874bd7 Extend bilingual_str support for tinyformat (Ryan Ofsky)
c361df90b9 scripted-diff: Remove double newlines after some init errors (Ryan Ofsky)
Pull request description:
Add common InitConfig function to deduplicate bitcoind and bitcoin-qt code reading config files and creating the datadir.
Noticed the duplicate code while reviewing #27073 and want to remove it because difference in bitcoin-qt and bitcoind behavior make it hard to evaluate changes like #27073
There are a few minor changes in behavior:
- In bitcoin-qt, when there is a problem reading the configuration file, the GUI error text has changed from "Error: Cannot parse configuration file:" to "Error reading configuration file:" to be consistent with bitcoind.
- In bitcoind, when there is a problem reading the settings.json file, the error text has changed from "Failed loading settings file" to "Settings file could not be read" to be consistent with bitcoin-qt.
- In bitcoind, when there is a problem writing the settings.json file, the error text has changed from "Failed saving settings file" to "Settings file could not be written" to be consistent with bitcoin-qt.
- In bitcoin-qt, if there datadir is not accessible (e.g. no permission to read), there is an normal error dialog showing "Error: filesystem error: status: Permission denied [.../settings.json]", instead of an uncaught exception.
ACKs for top commit:
Sjors:
Light review ACK 802cc1ef53
TheCharlatan:
ACK 802cc1ef53
achow101:
ACK 802cc1ef53
Tree-SHA512: 9c78d277e9ed595fa8ce286b97d2806e1ec06ddbbe7bd3434bd9dd7b456faf8d989f71231e97311f36edb9caaec645a50c730bd7514b8e0fe6e6f7741b13d981
The following scenarios are covered:
1) 10 UTXO with the same script:
partial spends is enabled --> outputs must not be grouped.
2) 10 UTXO with the same script:
partial spends disabled --> outputs must be grouped.
3) 20 UTXO, 10 one from scriptA + 10 from scriptB:
a) if partial spends is enabled --> outputs must not be grouped.
b) if partial spends is not enabled --> 2 output groups expected (one per script).
3) Try to add a negative output (value - fee < 0):
a) if "positive_only" is enabled --> negative output must be skipped.
b) if "positive_only" is disabled --> negative output must be added.
4) Try to add a non-eligible UTXO (due not fulfilling the min depth target for
"not mine" UTXOs) --> it must not be added to any group
5) Try to add a non-eligible UTXO (due not fulfilling the min depth target for
"mine" UTXOs) --> it must not be added to any group
6) Surpass the 'OUTPUT_GROUP_MAX_ENTRIES' size and verify that a second partial
group gets created.
Previous bilingual_str tinyformat::format accepted bilingual format strings,
but not bilingual arguments. Extend it to accept both. This is useful when
embedding one translated string inside another translated string, for example:
`strprintf(_("Error: %s"), message)` which would fail previously if `message`
was a bilingual_str.
511aa4f1c7 Add unit test for ChaCha20's new caching (Pieter Wuille)
fb243d25f7 Improve test vectors for ChaCha20 (Pieter Wuille)
93aee8bbda Inline ChaCha20 32-byte specific constants (Pieter Wuille)
62ec713961 Only support 32-byte keys in ChaCha20{,Aligned} (Pieter Wuille)
f21994a02e Use ChaCha20Aligned in MuHash3072 code (Pieter Wuille)
5d16f75763 Use ChaCha20 caching in FastRandomContext (Pieter Wuille)
38eaece67b Add fuzz test for testing that ChaCha20 works as a stream (Pieter Wuille)
5f05b27841 Add xoroshiro128++ PRNG (Martin Leitner-Ankerl)
12ff72476a Make unrestricted ChaCha20 cipher not waste keystream bytes (Pieter Wuille)
6babf40213 Rename ChaCha20::Seek -> Seek64 to clarify multiple of 64 (Pieter Wuille)
e37bcaa0a6 Split ChaCha20 into aligned/unaligned variants (Pieter Wuille)
Pull request description:
This is an alternative to #25354 (by my benchmarking, somewhat faster), subsumes #25712, and adds additional test vectors.
It separates the multiple-of-64-bytes-only "core" logic (which becomes simpler) from a layer around which performs caching/slicing to support arbitrary byte amounts. Both have their uses (in particular, the MuHash3072 code can benefit from multiple-of-64-bytes assumptions), plus the separation results in more readable code. Also, since FastRandomContext effectively had its own (more naive) caching on top of ChaCha20, that can be dropped in favor of ChaCha20's new built-in caching.
I thought about rebasing #25712 on top of this, but the changes before are fairly extensive, so redid it instead.
ACKs for top commit:
ajtowns:
ut reACK 511aa4f1c7
dhruv:
tACK crACK 511aa4f1c7
Tree-SHA512: 3aa80971322a93e780c75a8d35bd39da3a9ea570fbae4491eaf0c45242f5f670a24a592c50ad870d5fd09b9f88ec06e274e8aa3cefd9561d623c63f7198cf2c7
When generating new files as part of the Makefile the recipe is
sometimes suppressed with $(AM_V_GEN) and sometimes with `@`. We should
prefer $(AM_V_GEN), since this also prints the lines in silent mode.
This is arguably more in style with the current recipe echoing.
Before:
Generated test/data/script_tests.json.h
Now:
GEN test/data/script_tests.json.h
A side effect of this change is that the recipe for generating build.h
is now echoed on each make run. Arguably this makes its generation more
transparent.
The fuzzer goes through a sequence of operations that get applied to both a
real stack of CCoinsViewCache objects, and to simulation data, comparing
the two at the end.
Xoroshiro128++ is a fast non-cryptographic random generator.
Reference implementation is available at https://prng.di.unimi.it/
Co-Authored-By: Pieter Wuille <pieter@wuille.net>
9622fe64b8 test: move coins result test to wallet_tests.cpp (furszy)
f69347d058 test: extend and simplify availablecoins_tests (furszy)
212ccdf2c2 wallet: AvailableCoins, add arg to include/skip locked coins (furszy)
Pull request description:
Negative PR with extended test coverage :).
1) Cleaned duplicated code and added coverage for the 'AvailableCoins' incremental result.
2) The class `AvailableCoinsTestingSetup` inside `availablecoins_tests.cpp` is a plain copy
of `ListCoinsTestingSetup` that is inside `wallet_tests.cpp`.
So, deleted the file and moved the `BasicOutputTypesTest` test case to `wallet_tests.cpp`.
3) Added arg to include/skip locked coins from the `AvailableCoins` result. This is needed for point (1) as otherwise the wallet will spend the coins that we recently created due its closeness to the recipient amount.
Note: this last point comes from #25659 where I'm using the same functionality to clean/speedup another flow as well.
ACKs for top commit:
achow101:
ACK 9622fe64b8
theStack:
ACK 9622fe64b8
aureleoules:
reACK 9622fe64b8, nice cleanup!
Tree-SHA512: 1ed9133120bfe8815455d1ad317bb0ff96e11a0cc34ee8098716ab9b001749168fa649212b2fa14b330c1686cb1f29039ff1f88ae306db68881b0428c038f388
f1e89597c8 test: Drop no longer required bench output redirection (Hennadii Stepanov)
4dbcdf26a3 bench: Suppress output when running with `-sanity-check` option (Hennadii Stepanov)
Pull request description:
This change allows to simplify CI tests, and makes it easier to integrate the `bench_bitcoin` binary into CMake custom [targets](https://cmake.org/cmake/help/latest/command/add_custom_target.html) or [commands](https://cmake.org/cmake/help/latest/command/add_custom_command.html), as `COMMAND` does not support output redirection.
ACKs for top commit:
aureleoules:
tACK f1e89597c8. Ran as expected and is more practical than using an output redirection.
Tree-SHA512: 29086d428cccedcfd031c0b4514213cbc1670e35f955e8fd35cee212bc6f9616cf9f20d0cb984495390c4ae2c50788ace616aea907d44e0d6a905b9dda1685d8
files share the same purpose, and we shouldn't have wallet code
inside the test directory.
This later is needed to use wallet util functions in the bench
and test binaries without be forced to duplicate them.
3e9d0bea8d build: only run high priority benchmarks in 'make check' (furszy)
466b54bd4a bench: surround main() execution with try/catch (furszy)
3da7cd2a76 bench: explicitly make all current benchmarks "high" priority (furszy)
05b8c76232 bench: add "priority level" to the benchmark framework (furszy)
f1593780b8 bench: place benchmark implementation inside benchmark namespace (furszy)
Pull request description:
This is from today's meeting, a simple "priority level" for the benchmark framework.
Will allow us to run certain benchmarks while skip non-prioritized ones in `make check`.
By default, `bench_bitcoin` will run all the benchmarks. `make check`will only run the high priority ones,
and have marked all the existent benchmarks as "high priority" to retain the current behavior.
Could test it by modifying any benchmark priority to something different from "high", and
run `bench_bitcoin -priority-level=high` and/or `bench_bitcoin -priority-level=medium,low`
(the first command will skip the modified bench while the second one will include it).
Note: the second commit could be avoided by having a default arg value for the priority
level but.. an explicit set in every `BENCHMARK` macro call makes it less error-prone.
ACKs for top commit:
kouloumos:
re-ACK 3e9d0bea8d
achow101:
ACK 3e9d0bea8d
theStack:
re-ACK 3e9d0bea8d
stickies-v:
re-ACK 3e9d0bea8d
Tree-SHA512: ece59bf424c5fc1db335f84caa507476fb8ad8c6151880f1f8289562e17023aae5b5e7de03e8cbba6337bf09215f9be331e9ef51c791c43bce43f7446813b054
bcb0cacac2 reindex, log, test: fixes #21379 (mruddy)
Pull request description:
Fixes #21379.
The blocks/blk?????.dat files are mutated and become increasingly malformed, or corrupt, as a result of running the re-indexing process.
The mutations occur after the re-indexing process has finished, as new blocks are appended, but are a result of a re-indexing process miscalculation that lingers in the block manager's `m_blockfile_info` `nSize` data until node restart.
These additions to the blk files are non-fatal, but also not desirable.
That is, this is a form of data corruption that the reading code is lenient enough to process (it skips the extra bytes), but it adds some scary looking log messages as it encounters them.
The summary of the problem is that the re-index process double counts the size of the serialization header (magic message start bytes [4 bytes] + length [4 bytes] = 8 bytes) while calculating the blk data file size (both values already account for the serialization header's size, hence why it is over accounted).
This bug manifests itself in a few different ways, after re-indexing, when a new block from a peer is processed:
1. If the new block will not fit into the last blk file processed while re-indexing, while remaining under the 128MiB limit, then the blk file is flushed to disk and truncated to a size that is 8 greater than it should be. The truncation adds zero bytes (see `FlatFileSeq::Flush` and `TruncateFile`).
1. If the last blk file processed while re-indexing has logical space for the new block under the 128 MiB limit:
1. If the blk file was not already large enough to hold the new block, then the zeros are, in effect, added by `fseek` when the file is opened for writing. Eight zero bytes are added to the end of the last blk file just before the new block is written. This happens because the write offset is 8 too great due to the miscalculation. The result is 8 zero bytes between the end of the last block and the beginning of the next block's magic + length + block.
1. If the blk file was already large enough to hold the new block, then the current existing file contents remain in the 8 byte gap between the end of the last block and the beginning of the next block's magic + length + block. Commonly, when this occcurs, it is due to the blk file containing blocks that are not connected to the block tree during reindex and are thus left behind by the reindex process and later overwritten when new blocks are added. The orphaned blocks can be valid blocks, but due to the nature of concurrent block download, the parent may not have been retrieved and written by the time the node was previously shutdown.
ACKs for top commit:
LarryRuane:
tested code-review ACK bcb0cacac2
ryanofsky:
Code review ACK bcb0cacac2. This is a disturbing bug with an easy fix which seems well-worth merging.
mzumsande:
ACK bcb0cacac2 (reviewed code and did some testing, I agree that it fixes the bug).
w0xlt:
tACK bcb0cacac2
Tree-SHA512: acc97927ea712916506772550451136b0f1e5404e92df24cc05e405bb09eb6fe7c3011af3dd34a7723c3db17fda657ae85fa314387e43833791e9169c0febe51
Rename `BResult` class to `util::Result` and update the class interface to be
more compatible with `std::optional` and with a full-featured result class
implemented in https://github.com/bitcoin/bitcoin/pull/25665. Motivation for
this change is to update existing `BResult` usages now so they don't have to
change later when more features are added in #25665.
This change makes the following improvements originally implemented in #25665:
- More explicit API. Drops potentially misleading `BResult` constructor that
treats any bilingual string argument as an error. Adds `util::Error`
constructor so it is never ambiguous when a result is being assigned an error
or non-error value.
- Better type compatibility. Supports `util::Result<bilingual_str>` return
values to hold translated messages which are not errors.
- More standard and consistent API. `util::Result` supports most of the same
operators and methods as `std::optional`. `BResult` had a less familiar
interface with `HasRes`/`GetObj`/`ReleaseObj` methods. The Result/Res/Obj
naming was also not internally consistent.
- Better code organization. Puts `src/util/` code in the `util::` namespace so
naming reflects code organization and it is obvious where the class is coming
from. Drops "B" from name because it is undocumented what it stands for
(bilingual?)
- Has unit tests.
71d1d13627 test: add unit test for AvailableCoins (josibake)
da03cb41a4 test: functional test for new coin selection logic (josibake)
438e04845b wallet: run coin selection by `OutputType` (josibake)
77b0707206 refactor: use CoinsResult struct in SelectCoins (josibake)
2e67291ca3 refactor: store by OutputType in CoinsResult (josibake)
Pull request description:
# Concept
Following https://github.com/bitcoin/bitcoin/pull/23789, Bitcoin Core wallet will now generate a change address that matches the payment address type. This improves privacy by not revealing which of the outputs is the change at the time of the transaction in scenarios where the input address types differ from the payment address type. However, information about the change can be leaked in a later transaction. This proposal attempts to address that concern.
## Leaking information in a later transaction
Consider the following scenario:
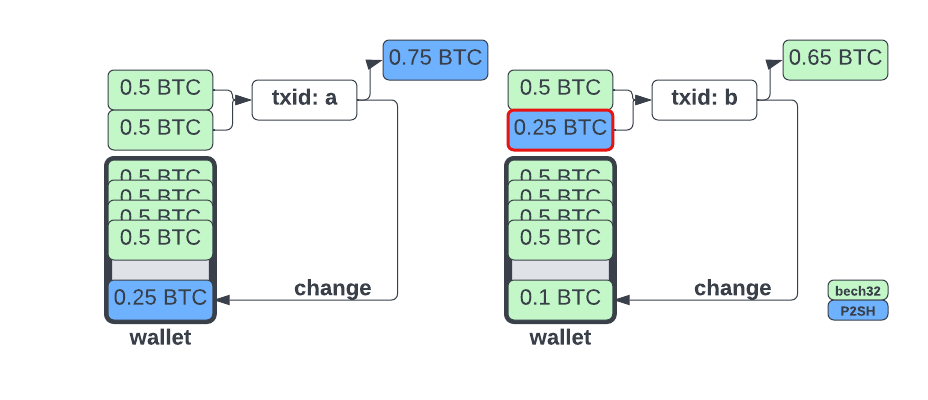
1. Alice has a wallet with bech32 type UTXOs and pays Bob, who gives her a P2SH address
2. Alice's wallet generates a P2SH change output, preserving her privacy in `txid: a`
3. Alice then pays Carol, who gives her a bech32 address
4. Alice's wallet combines the P2SH UTXO with a bech32 UTXO and `txid: b` has two bech32 outputs
From a chain analysis perspective, it is reasonable to infer that the P2SH input in `txid: b` was the change from `txid: a`. To avoid leaking information in this scenario, Alice's wallet should avoid picking the P2SH output and instead fund the transaction with only bech32 Outputs. If the payment to Carol can be funded with just the P2SH output, it should be preferred over the bech32 outputs as this will convert the P2SH UTXO to bech32 UTXOs via the payment and change outputs of the new transaction.
**TLDR;** Avoid mixing output types, spend non-default `OutputTypes` when it is economical to do so.
# Approach
`AvailableCoins` now populates a struct, which makes it easier to access coins by `OutputType`. Coin selection tries to find a funding solution by each output type and chooses the most economical by waste metric. If a solution can't be found without mixing, coin selection runs over the entire wallet, allowing mixing, which is the same as the current behavior.
I've also added a functional test (`test/functional/wallet_avoid_mixing_output_types.py`) and unit test (`src/wallet/test/availablecoins_tests.cpp`.
ACKs for top commit:
achow101:
re-ACK 71d1d13627
aureleoules:
ACK 71d1d13627.
Xekyo:
reACK 71d1d13627 via `git range-diff master 6530d19 71d1d13`
LarryRuane:
ACK 71d1d13627
Tree-SHA512: 2e0716efdae5adf5479446fabc731ae81d595131d3b8bade98b64ba323d0e0c6d964a67f8c14c89c428998bda47993fa924f3cfca1529e2bd49eaa4e31b7e426
Test each component of the RBF policy in isolation. Unlike the RBF
functional tests, these do not rely on things like RPC results, mempool
submission, etc.
{kind=link}
{kind=link}
{kind=link}
{kind=link}